深入剖析printf函数(下):---形参列表和格式化输出是如何做到的?
By Long Luo
一、引言
在上一篇 深入剖析printf函数(上):如何不借助第三方库在屏幕上输出”Hello World”? 里,我们已经实现了用汇编语言在屏幕上输出了“Hello World”, 迈出了万里长征的第一步,但是我们知道实际的printf的功能是十分强大的,它和scanf一样属于标准输入输出的一种格式化函数,我们一般是这样使用它的:1
printf()的基本形式:printf("格式控制字符串",变量列表);
二、格式化输出
printf()函数是格式输出函数,请求printf()打印变量的指令取决与变量的类型.
例如,在打印整数是使用%d符号,在打印字符是用%c符号.这些符号被称为转换说明.因为它们指定了如何不数据转换成可显示的形式.
下列列出的是ANSI C标准printf()提供的各种转换说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18转换说明及作为结果的打印输出
%a 浮点数、十六进制数字和p-记数法(C99)
%A 浮点数、十六进制数字和p-记法(C99)
%c 一个字符
%d 有符号十进制整数
%e 浮点数、e-记数法
%E 浮点数、E-记数法
%f 浮点数、十进制记数法
%g 根据数值不同自动选择%f或%e.
%G 根据数值不同自动选择%f或%e.
%i 有符号十进制数(与%d相同)
%o 无符号八进制整数
%p 指针
%s 字符串
%u 无符号十进制整数
%x 使用十六进制数字0f的无符号十六进制整数
%X 使用十六进制数字0f的无符号十六进制整数
%% 打印一个百分号
三、形参列表的读入
printf函数的参数列表是如下的形式:1
int printf(const char *fmt, ...)
类似于上面参数列表中的token:…,这个是可变形参的一种写法。当传递参数的个数不确定时,就可以用这种方式来表示。
但是电脑比程序员更笨,函数体必须知道具体调用时参数的个数才能保证顺利执行,那么我们必须寻找一种方法来了解参数的个数。
让我们先回到代码中来:
1 | /************************************************************************************ |
如上面代码中的: 1
va_list arg = (va_list)((char*)(&fmt) + 4);
而va_list的定义:1
typedef char *va_list
这说明它是一个字符指针。
其中的:(char*)(&fmt) + 4) 表示的是...中的第一个参数。
大家肯定很迷惑,不急,再详细解释:1
C语言中,参数压栈的方向是从右往左。也就是说,当调用printf函数的适合,先是最右边的参数入栈。
fmt是一个指针,这个指针指向第一个const参数(const char *fmt)中的第一个元素。
fmt也是个变量,它的位置,是在栈上分配的,它也有地址。
对于一个char 类型的变量,它入栈的是指针,而不是这个char 型变量。
换句话说: 你sizeof(p) (p是一个指针,假设p=&i,i为任何类型的变量都可以)得到的都是一个固定的值。(我的计算机中都是得到的4)
当然,我还要补充的一点是:栈是从高地址向低地址方向增长的。
现在我想你该明白了:为什么说(char*)(&fmt) + 4) 表示的是...中的第一个参数的地址。
为毛我还是不明白啊????
不急,我给你更直观的解释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/******************************************************************************************
可变参数函数调用原理(其中涉及的数字皆为举例)
===========================================================================================
i = 0x23;
j = 0x78;
char fmt[] = "%x%d";
printf(fmt, i, j);
push j
push i
push fmt
call printf
add esp, 3 * 4
┃ HIGH ┃ ┃ HIGH ┃
┃ ... ┃ ┃ ... ┃
┣━━━━━━━━━━┫ ┣━━━━━━━━━━┫
┃ ┃ 0x32010┃ '\0' ┃
┣━━━━━━━━━━┫ ┣━━━━━━━━━━┫
0x3046C┃ 0x78 ┃ 0x3200c┃ d ┃
┣━━━━━━━━━━┫ ┣━━━━━━━━━━┫
arg = 0x30468┃ 0x23 ┃ 0x32008┃ % ┃
┣━━━━━━━━━━┫ ┣━━━━━━━━━━┫
0x30464┃ 0x32000 ───╂────┐ 0x32004┃ x ┃
┣━━━━━━━━━━┫ │ ┣━━━━━━━━━━┫
┃ ┃ └──→ 0x32000┃ % ┃
┣━━━━━━━━━━┫ ┣━━━━━━━━━━┫
┃ ... ┃ ┃ ... ┃
┃ LOW ┃ ┃ LOW ┃
实际上,调用 vsprintf 的情形是这样的:
vsLprintf(buf, 0x32000, 0x30468);
******************************************************************************************/
下面我们来看看下一句:1
i = vsLprintf(buf, fmt, arg);
这句起什么作用呢?
让我们进入下一节:对参数进行格式化处理。
四、参数格式化输出
让我们来看看vsLprintf(buf, fmt, arg)是什么函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83int vsLprintf(char *buf, const char *fmt, va_list args)
{
char *p;
int m;
char inner_buf[STR_DEFAULT_LEN];
char cs;
int align_nr;
va_list p_next_arg = args;
for (p=buf; *fmt; fmt++) {
if (*fmt != '%') {
*p++ = *fmt;
continue;
}
else { /* a format string begins */
align_nr = 0;
}
fmt++;
if (*fmt == '%') {
*p++ = *fmt;
continue;
}
else if (*fmt == '0') {
cs = '0';
fmt++;
}
else {
cs = ' ';
}
while (((unsigned char)(*fmt) >= '0') && ((unsigned char)(*fmt) <= '9')) {
align_nr *= 10;
align_nr += *fmt - '0';
fmt++;
}
char * q = inner_buf;
memset(q, 0, sizeof(inner_buf));
switch (*fmt) {
case 'c':
*q++ = *((char*)p_next_arg);
p_next_arg += 4;
break;
case 'x':
m = *((int*)p_next_arg);
i2a(m, 16, &q);
p_next_arg += 4;
break;
case 'd':
m = *((int*)p_next_arg);
if (m < 0) {
m = m * (-1);
*q++ = '-';
}
i2a(m, 10, &q);
p_next_arg += 4;
break;
case 's':
strcpy(q, (*((char**)p_next_arg)));
q += strlen(*((char**)p_next_arg));
p_next_arg += 4;
break;
default:
break;
}
int k;
for (k = 0; k < ((align_nr > strlen(inner_buf)) ? (align_nr - strlen(inner_buf)) : 0); k++) {
*p++ = cs;
}
q = inner_buf;
while (*q) {
*p++ = *q++;
}
}
*p = 0;
return (p - buf);
}
这个函数起什么作用呢?
我们回想下printf起什么作用呢?
哦,printf接受一个格式化的命令,并把指定的匹配的参数格式化输出。 好的,我们再看看i = vsLprintf(buf, fmt, arg);
vsLprintf返回的是一个长度值,那这个值是什么呢?
会不会是打印出来的字符串的长度呢?
没错,返回的就是要打印出来的字符串的长度。
其实看看printf中后面的一句:LLprint(buf, i)。
介个是干啥的?
什么,你不知道,那赶紧看上一篇文章。 总结:vsLprintf的作用就是格式化。
它接受确定输出格式的格式字符串fmt。用格式字符串对个数变化的参数进行格式化,产生格式化输出。
我们也可以看看一个串口的printf的实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438//*****************************************************************************
//
//! A simple UART based printf function supporting \%c, \%d, \%p, \%s, \%u,
//! \%x, and \%X.
//!
//! \param pcString is the format string.
//! \param ... are the optional arguments, which depend on the contents of the
//! format string.
//!
//! This function is very similar to the C library <tt>fprintf()</tt> function.
//! All of its output will be sent to the UART. Only the following formatting
//! characters are supported:
//!
//! - \%c to print a character
//! - \%d to print a decimal value
//! - \%s to print a string
//! - \%u to print an unsigned decimal value
//! - \%x to print a hexadecimal value using lower case letters
//! - \%X to print a hexadecimal value using lower case letters (not upper case
//! letters as would typically be used)
//! - \%p to print a pointer as a hexadecimal value
//! - \%\% to print out a \% character
//!
//! For \%s, \%d, \%u, \%p, \%x, and \%X, an optional number may reside
//! between the \% and the format character, which specifies the minimum number
//! of characters to use for that value; if preceded by a 0 then the extra
//! characters will be filled with zeros instead of spaces. For example,
//! ``\%8d'' will use eight characters to print the decimal value with spaces
//! added to reach eight; ``\%08d'' will use eight characters as well but will
//! add zeroes instead of spaces.
//!
//! The type of the arguments after \e pcString must match the requirements of
//! the format string. For example, if an integer was passed where a string
//! was expected, an error of some kind will most likely occur.
//!
//! \return None.
//
//*****************************************************************************
void
UARTprintf(const char *pcString, ...)
{
unsigned long ulIdx, ulValue, ulPos, ulCount, ulBase, ulNeg;
char *pcStr, pcBuf[16], cFill;
va_list vaArgP;
//
// Check the arguments.
//
ASSERT(pcString != 0);
//
// Start the varargs processing.
//
va_start(vaArgP, pcString);
//
// Loop while there are more characters in the string.
//
while(*pcString)
{
//
// Find the first non-% character, or the end of the string.
//
for(ulIdx = 0; (pcString[ulIdx] != '%') && (pcString[ulIdx] != '\0');
ulIdx++)
{
}
//
// Write this portion of the string.
//
UARTwrite(pcString, ulIdx);
//
// Skip the portion of the string that was written.
//
pcString += ulIdx;
//
// See if the next character is a %.
//
if(*pcString == '%')
{
//
// Skip the %.
//
pcString++;
//
// Set the digit count to zero, and the fill character to space
// (i.e. to the defaults).
//
ulCount = 0;
cFill = ' ';
//
// It may be necessary to get back here to process more characters.
// Goto's aren't pretty, but effective. I feel extremely dirty for
// using not one but two of the beasts.
//
again:
//
// Determine how to handle the next character.
//
switch(*pcString++)
{
//
// Handle the digit characters.
//
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
{
//
// If this is a zero, and it is the first digit, then the
// fill character is a zero instead of a space.
//
if((pcString[-1] == '0') && (ulCount == 0))
{
cFill = '0';
}
//
// Update the digit count.
//
ulCount *= 10;
ulCount += pcString[-1] - '0';
//
// Get the next character.
//
goto again;
}
//
// Handle the %c command.
//
case 'c':
{
//
// Get the value from the varargs.
//
ulValue = va_arg(vaArgP, unsigned long);
//
// Print out the character.
//
UARTwrite((char *)&ulValue, 1);
//
// This command has been handled.
//
break;
}
//
// Handle the %d command.
//
case 'd':
{
//
// Get the value from the varargs.
//
ulValue = va_arg(vaArgP, unsigned long);
//
// Reset the buffer position.
//
ulPos = 0;
//
// If the value is negative, make it positive and indicate
// that a minus sign is needed.
//
if((long)ulValue < 0)
{
//
// Make the value positive.
//
ulValue = -(long)ulValue;
//
// Indicate that the value is negative.
//
ulNeg = 1;
}
else
{
//
// Indicate that the value is positive so that a minus
// sign isn't inserted.
//
ulNeg = 0;
}
//
// Set the base to 10.
//
ulBase = 10;
//
// Convert the value to ASCII.
//
goto convert;
}
//
// Handle the %s command.
//
case 's':
{
//
// Get the string pointer from the varargs.
//
pcStr = va_arg(vaArgP, char *);
//
// Determine the length of the string.
//
for(ulIdx = 0; pcStr[ulIdx] != '\0'; ulIdx++)
{
}
//
// Write the string.
//
UARTwrite(pcStr, ulIdx);
//
// Write any required padding spaces
//
if(ulCount > ulIdx)
{
ulCount -= ulIdx;
while(ulCount--)
{
UARTwrite(" ", 1);
}
}
//
// This command has been handled.
//
break;
}
//
// Handle the %u command.
//
case 'u':
{
//
// Get the value from the varargs.
//
ulValue = va_arg(vaArgP, unsigned long);
//
// Reset the buffer position.
//
ulPos = 0;
//
// Set the base to 10.
//
ulBase = 10;
//
// Indicate that the value is positive so that a minus sign
// isn't inserted.
//
ulNeg = 0;
//
// Convert the value to ASCII.
//
goto convert;
}
//
// Handle the %x and %X commands. Note that they are treated
// identically; i.e. %X will use lower case letters for a-f
// instead of the upper case letters is should use. We also
// alias %p to %x.
//
case 'x':
case 'X':
case 'p':
{
//
// Get the value from the varargs.
//
ulValue = va_arg(vaArgP, unsigned long);
//
// Reset the buffer position.
//
ulPos = 0;
//
// Set the base to 16.
//
ulBase = 16;
//
// Indicate that the value is positive so that a minus sign
// isn't inserted.
//
ulNeg = 0;
//
// Determine the number of digits in the string version of
// the value.
//
convert:
for(ulIdx = 1;
(((ulIdx * ulBase) <= ulValue) &&
(((ulIdx * ulBase) / ulBase) == ulIdx));
ulIdx *= ulBase, ulCount--)
{
}
//
// If the value is negative, reduce the count of padding
// characters needed.
//
if(ulNeg)
{
ulCount--;
}
//
// If the value is negative and the value is padded with
// zeros, then place the minus sign before the padding.
//
if(ulNeg && (cFill == '0'))
{
//
// Place the minus sign in the output buffer.
//
pcBuf[ulPos++] = '-';
//
// The minus sign has been placed, so turn off the
// negative flag.
//
ulNeg = 0;
}
//
// Provide additional padding at the beginning of the
// string conversion if needed.
//
if((ulCount > 1) && (ulCount < 16))
{
for(ulCount--; ulCount; ulCount--)
{
pcBuf[ulPos++] = cFill;
}
}
//
// If the value is negative, then place the minus sign
// before the number.
//
if(ulNeg)
{
//
// Place the minus sign in the output buffer.
//
pcBuf[ulPos++] = '-';
}
//
// Convert the value into a string.
//
for(; ulIdx; ulIdx /= ulBase)
{
pcBuf[ulPos++] = g_pcHex[(ulValue / ulIdx) % ulBase];
}
//
// Write the string.
//
UARTwrite(pcBuf, ulPos);
//
// This command has been handled.
//
break;
}
//
// Handle the %% command.
//
case '%':
{
//
// Simply write a single %.
//
UARTwrite(pcString - 1, 1);
//
// This command has been handled.
//
break;
}
//
// Handle all other commands.
//
default:
{
//
// Indicate an error.
//
UARTwrite("ERROR", 5);
//
// This command has been handled.
//
break;
}
}
}
}
//
// End the varargs processing.
//
va_end(vaArgP);
}
写的很精彩,是不是?
五、应用层的使用
通过上面的工作,我们已经实现了一个自己的printf函数:LLprintf
LLprintf的功能和我们标准库的printf一样强大,我们可以在上层如此使用LLprintf:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/************************************************************************************
** File: - Z:\code\c\LLprintf\print2.1\app.c
**
** Copyright (C), Long.Luo, All Rights Reserved!
**
** Description:
** app.c --- The Application Level.
**
** Version: 2.1
** Date created: 23:53:41,24/01/2013
** Author: Long.Luo
**
** --------------------------- Revision History: --------------------------------
** <author> <data> <desc>
**
************************************************************************************/
int main(void)
{
char *welcome = " A Tiny Demo show the LLprintf ";
char *program_name = "LLprintf";
char *program_author = "Long.Luo";
char *date = "Jan. 24th, 2013";
float program_version = 2.1;
Lprintf("%s\n\n", welcome);
Lprintf("\t\t%s, version %f \n\n", program_name, program_version);
Lprintf("\tCreated by %s, %s.\n\n", program_author, date);
return 0;
}
make一下,我们再来看看输出结果: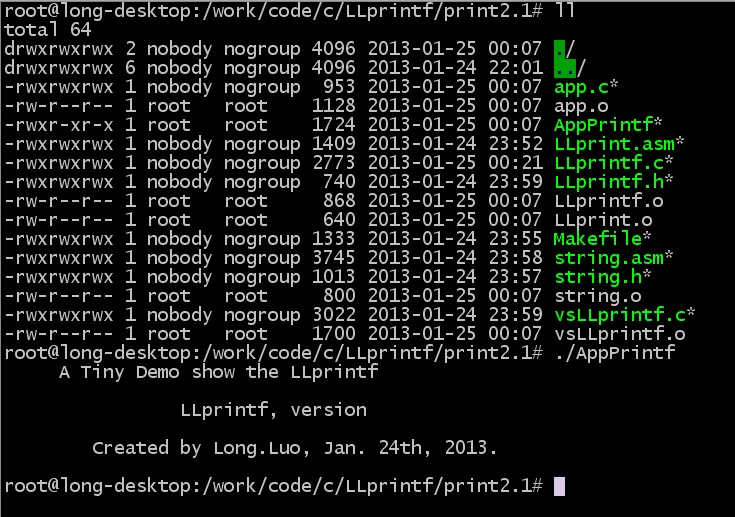
这样我们就了解了printf函数的前因后果。
***聪明的你,弄明白了吗?^_^***
文章修改历史
- Modified By Long Luo at 2018年10月2日03点44分 in Shenzhen, China.
- 修改图床 2024.03.03 in Shenzhen.